There are currently three output modes available, namely No filter, Latin1 hexadecimal string, and Unicode hexadecimal string.
Are there any differences between them? Let’s use the ls instruction to demonstrate their differences.
1.No filter
The data is not subjected to any formatting processing, but will be encoded and converted to UNCODE display.
Note: After encoding conversion.

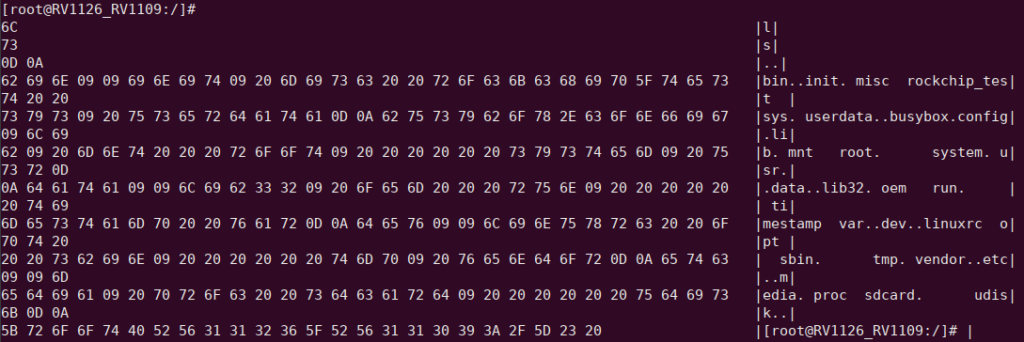
2.Latin1 hex string
The data will be displayed in hexadecimal format according to the Latin1 character set.
Note: After the encoding conversion, because the Latin1 character processing was performed before the conversion, the encoding conversion is completely consistent before and after the conversion.
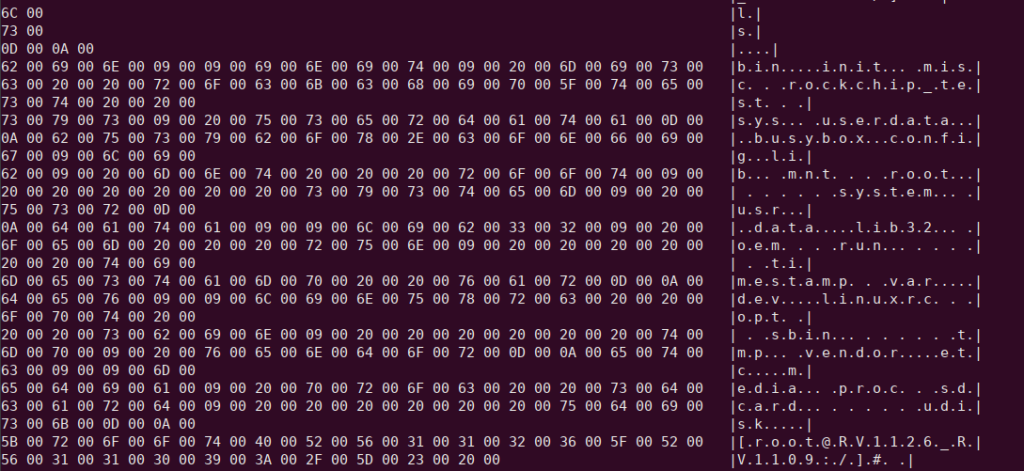
3.Unicode hex string
The data will be converted to Unicode encoding based on the device encoding before being displayed in hexadecimal format.
Note: Before encoding conversion